

基于遗传算法与BP神经网络的支架跟机自动化研究
Research on automation of support based on genetic algorithm and BP neural network
-
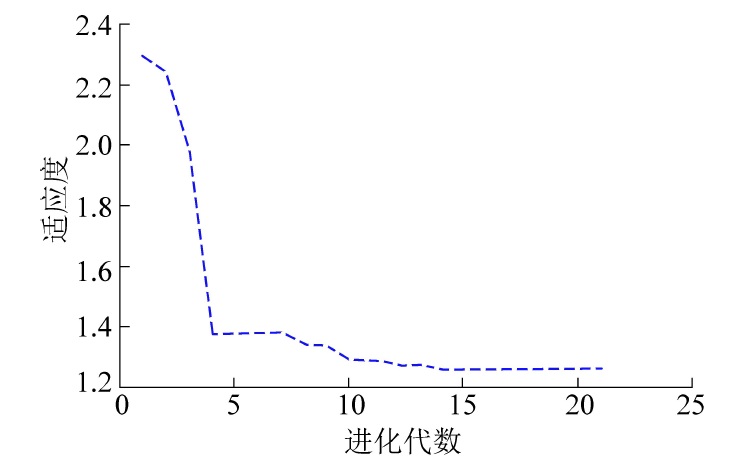
摘要: 针对综采工作面液压支架跟机自动化过程中移架动作存在的丢架、推移不到位等问题,提出了基于遗传算法(GA)与BP神经网络组合模型的控制方法。通过建立BP神经网络控制器为主体的反馈控制,将支架的运动参数作为模型的输入,神经网络控制器用来计算实际输出与理想输出之间误差,判别是否需要回调控制,并添加遗传算法来优化更新模型的各层阈值和权值,从而得到网络模型的最优解,最终由执行部分来完成输出动作。组合网络模型具有良好的非线性特性,可以更好的满足非线性环境,利用神经网络的预测值与实际输出的差值来得到拟合曲线。通过对BP神经网络模型、GA模型、GA-BP组合模型的均方误差(mse)分析,判断出GA-BP组合模型具有更快的训练速度和更高的预测准确率。相比较于单一的BP神经网络模型和GA模型,GA-BP组合模型可以很大程度地提高液压支架跟机过程中的推移精度,从而更好地适应综采工作面的环境和设备变化。基于对模型稳定性的分析,绘制组合网络的适应度曲线,种群在第5次迭代后趋于收敛,在第5次到第15次迭代的适应度值就已基本达到稳定,在迭代第15次后种群已达到最优参数集且恒定不变。采用上述方案的液压支架电液控制系统能够自主感知设备各项运动参数的变化,实现支架自身的静态调整和动态演化,可为综采工作面无人化建设提供技术支撑。Abstract: In view of the problems of frame loss and improper support movement in the automatic process of hydraulic support following machine in fully mechanized mining working, a control method was proposed based on Genetic Algorithm (GA) and BP neural network combined model. Through the establishment of BP neural network controller as the main feedback control, the motion parameters of the support are used as the input of the model. The neural network controller is used to calculate the error between the actual output and the ideal output, to determine whether callback control is required. In order to optimize the thresholds and weights of each layer of the updated model to obtain the optimal solution of the network model, and finally get the optimal solution of the network model, and the execution part completes the output action. The combined network model has good nonlinear characteristics and can better meet the nonlinear environment. The difference between the predicted value of the neural network and the actual output is used to obtain the fitting curve. By analyzing the mean square error (mse) of the BP neural network model, GA model, and BP-GA combined model, it is justified that the GA-BP combined model has faster training speed and higher prediction accuracy. Compared with a single BP neural network model and GA model, the GA-BP combined model can greatly improve the accuracy of the hydraulic support in the process of following the machine, so as to better adapt to the changes in the environment and equipment in the fully mechanized mining working. Based on the analysis of model stability, the fitness curve of the combined model was drawn. The population tends to converge after the 5th iteration, and the fitness value from the 5th to 15th iteration is basically stable, and after the 15th iteration the population has reached the optimal parameter and became constant. The hydraulic support electro-hydraulic control system adopting the above schemecan autonomously sense the changes of various motion parameters of the equipment, realizethe static adjustment and dynamic evolution of the support itself, and provide technical support for the unmanned operation of the fully mechanized mining faces.
-
0. 引 言
露天煤矿是当今世界能源供应体系中的重要组成部分,其生产本质和矿卡运输共同构成了煤炭产业的核心。在这个信息时代,电力是人类社会的生活之源,而煤炭则是电力生产的不可或缺的燃料[1]。因此,了解露天煤矿的生产过程和矿卡运输的角色对于理解能源生产的本质至关重要[2]。
有人矿卡驾驶速度的预测是智能交通研究领域中重要的研究方向,速度的预测精度直接决定了调度模型中路径权重以及模型规划结果的现实性[3-4]。气象环境对露天矿山运输矿卡车速度有着重要的影响。这种影响涉及多个方面,包括天气条件、气温、风速、降水和其他气象因素。以下是一些关键因素:
不同的气象条件会对露天矿山内的矿卡运输速度产生直接影响。恶劣天气条件,如暴雨、暴风雪或雷暴,通常会导致运输速度的显著下降,甚至暂停。这是因为这些极端天气条件增加了道路上的危险性,如积雪、结冰、泥浆和泥水。气温的极端变化,特别是极端低温,对矿卡的机械性能产生不利影响。在极寒条件下,机油变得黏稠,发动机启动需要更多时间,机械部件容易受损。高温也可能导致冷却系统不足,需要额外的冷却。强风速度对矿卡的稳定性产生负面影响,尤其是在大型矿卡行驶时。风力可以导致车辆偏离轨道,增加翻车的风险。
降水会直接影响道路状况,从而影响矿卡的速度。大雨可能导致洪水和道路损坏,从而阻碍矿卡的正常运输。此外,降水还会导致路面湿滑,增加制动距离。气象条件如雾、浓雾或沙尘暴降低了驾驶员的视野,从而降低了矿卡的行驶速度。能见度降低会导致驾驶员难以识别前方道路状况,增加事故风险。矿山所在地区的海拔高度可能会对矿卡的性能产生影响。在高海拔地区,空气稀薄,引擎性能可能下降,导致速度减缓。
综上,气象环境对露天矿山运输矿卡车速度的影响是一个复杂而关键的研究领域。深入研究这一问题有助于制定更科学的运输策略,以确保在各种气象条件下实现高效和安全运输。煤矿行业需要积极采取措施,包括天气监测、设备维护和驾驶员培训,以最大程度地减轻气象因素对矿卡运输速度的影响。同时,未来的研究还可以集中于开发更为可持续的运输解决方案,以减少对环境的负面影响。
矿卡速度的预测对矿山和采矿行业的调度系统具有积极的影响[5-7],可以提高生产效率、降低成本、提高安全性,并提供更灵活的决策支持。这种技术是矿山运营优化的一部分,有望为煤矿和采矿行业带来显著的效益[8]。
笔者通过露天矿有人驾驶矿卡速度预测研究,一方面可以用来改进露天矿动态调度模型,提高模型规划质量,另一方面参照露天矿山整体地形结构,梳理露天矿采装运输系统作业流程,研究不同曲率和坡度车辆的行车规律,在露天矿智能调度系统的研究中,更好地借鉴智能交通流域的最新研究思路和研究成果,增强调度系统应对矿区突发事件的能力[9-10]。
综上所述,笔者在露天矿人工驾驶矿卡车速研究工作主要包括以下几个方面:1)分析人工驾驶行为习惯,提取出人工驾驶在不同路段上车速特征。2)首先需要对人工驾驶数据进行预处理,随后从曲率和坡度两个维度分析车辆行车速度规律。最终,根据提取结果,进行车辆行为特性拟合,得出人工行驶车速与全矿地图的映射表。3)对比研究基于随机森林(random forest)和XGBoost的速度预测模型,选取最优模型构建矿卡车速预测模型,通过增加气象数据影响因素,利用实时获得的车辆运行数据进行实时预测。
1. 相关技术方案
1.1 智能调度算法
露天矿矿卡智能调度方案主要包含2部分:构建矿山生产模型及开发智能调度算法。矿山生产模型是指通过数学表达与编程语言模拟露天矿生产中的“装—运—卸”过程[11]。智能调度算法是指通过人工智能算法求解矿山生产模型并得到最优或近优解。如图1所示,矿山生产模型执行智能调度算法求得调度任务,并将运行得到的工作时长、油量消耗等信息返回调度算法之中,供调度算法进行迭代优化。
![]() 图 1 智能调度算法闭环框图Figure 1. Closed-loop block diagram of the intelligent scheduling algorithm
图 1 智能调度算法闭环框图Figure 1. Closed-loop block diagram of the intelligent scheduling algorithm智能调度算法用于求解露天矿生产模型得到最优或近优解,即高效生产调度计划。露天矿智能调度是典型的组合优化问题,具有NP-hard特性,目前常见的求解方式包含以下4大类:
开源求解器:包括$ \mathrm{o}\mathrm{r}\mathrm{t}\mathrm{o}\mathrm{o}\mathrm{l}\mathrm{s} $、$ \mathrm{j}\mathrm{s}\mathrm{p}\mathrm{r}\mathrm{i}\mathrm{t} $、$ \mathrm{c}\mathrm{p}\mathrm{l}\mathrm{e}\mathrm{x} $等,其优势为开源框架、简单易行,但存在结合模型需求的二次开发困难、不满足露天矿智能调度复杂场景需求等问题。
精确算法:包括分支界定法、列生成法等,其优势为能够求得模型的最优解,但存在计算量巨大,随变量数指数级增长的问题,无法处理复杂约束下多变量的智能调度模型。
深度学习算法:包括深度强化学习、图神经网络等,其优势是能处理大规模、强约束的优化模型,但存在算法黑盒、泛化能力差、无法保证鲁棒性等问题,不适合矿卡智能调度。
启发式算法:包括遗传算法、蚁群算法、粒子群算等,虽然存在着计算量较高,较容易陷入局部最优解的问题,但其具有能够处理决策变量较多的问题,可得到近似最优解的可行解的优势。
综上所述,本项目采用启发式算法进行露天矿生产模型[12]。在启发式算法中遗传算法最广为使用于矿卡智能调度类的组合优化问题。遗传算法的基本思想就是模仿自然进化过程,通过对群体中具有某种结构形式的个体进行遗传操作,从而生成新的群体,逐渐逼近最优解。在求解过程中设定一个固定规模的种群,种群中的每个个体都表示问题的一个可能解,个体适应环境的程度用适应度函数判断,适应度差的个体被淘汰,适应度好的个体得以继续繁衍,繁衍的过程中可能要经过选择、交叉、变异,形成新的族群,如此往复,最后得到更多更好的解。
矿卡行驶速度通常会受多种因素的影响,经过人工经验及历史数值主成分分析可知,主要影响矿卡行驶速度的因素包括天气情况、车辆动力学特性及道路结构等,其中具体因素分析见表1。
表 1 矿卡车速预测输入数据Table 1. Mining truck speed prediction input data天气 道路交通 车辆 大雾、浓尘 降雨、降雪 道路饱和程度 道路坡度弯度 载重状态 车辆型号 降低矿卡
行驶能见度。影响道路路面
附着系数。道路上车流量会直接影响
车辆的行驶行为坡度、弯路会降低
矿卡行驶速度车辆的重载与否同样
会影响运行时间车辆的动力学模型是影响
行驶速度的主要因素天气变化是影响露天矿生产的关键因素,降雨、降雪将影响矿区道路附着系数,使得矿卡易失控甚至出现侧翻等严重事故;大雾、浓尘导致能见度降低,驾驶员及无人驾驶传感器感知范围受限。为保证矿卡行驶安全,在出现异常天气下矿卡通常会降速行驶或停车,因此挖掘异常天气与矿卡行驶速度间的数学关系并进行实时准确预测是实现矿卡动态调度的核心。
在露天矿山的采矿区域,气象传感器通常会被放置在地面或靠近地面的位置,以测量气温、湿度、风速、风向等参数。这有助于监测矿山内的气象条件,特别是在作业区域。
车载黑匣子是专为智能车辆开发研制的车辆行驶数据记录装置,用于记录车辆运行关键数据[13]。车载黑匣子数据信息内容包括:日期和时间,定位状态,位置,方向,速度,姿态等,障碍物信息,道路边界信息,系统输出的决策动作,系统输出的控车指令,故障类型,智能交互记录等。
笔者使用的数据全部取自南露天煤矿车载通信系统和环境感知系统的真实数据。最终筛选了以下13个特征作为输入数据,车速作为输出数据。经度、纬度、方向角、GPS状态1、卫星数、高程、当前时间与车速等数据取自车载黑匣子。风速、降雨量、气温、湿度和降雪量取自气象传感器。
2. 实验验证与分析
2.1 速度分布
2.1.1 数据清洗
在计算速度分布前需要对数据进行预处理。将其中噪声数据滤除,以排除噪声对后续统计的影响。同时将时间特征列和设备号列转化为浮点型。时间列特征转换公式如下所示:
$$ Time = Hour + \frac{{Minute}}{{60}} + \frac{{Second}}{{3600}} $$ (1) 接下来要对数据进行数据清洗,数据清洗技术方案如图2所示。
1)筛选人工驾驶模式下,车辆前向行驶数据;
2)对于车辆速度小于5 km/h的人工驾驶数据,将其滤除;
3)对于车辆速度大于40 km/h的人工驾驶数据,将其滤除;
清洗完成后,将剩余数据作为速度分布提取算法输入。算法流程图如图2所示.
2.1.2 曲率区间计算
基于人工驾驶文件中的经纬度等,按照1 s时间间隔(人工上报频率为1 Hz),计算人工驾驶车辆在单位时间内行驶曲率半径值。具体计算过程为将相邻时间的前点及其后一个点的WGS84坐标转换成UTM坐标,计算2点距离差;再记录2点航向角差值,通过公式计算对应的曲率k:
$$ k=\frac{180\times\Delta s}{\Delta\theta\times\mathrm{\pi}} $$ (2) 其中,Δs为相邻时间内对应车辆位置点间的距离差,Δθ为相邻时间内对应车辆位置点对应的航向角偏差。对应该曲率点的车辆行驶速度v计算如下:
$$ v = \frac{{\Delta s}}{{\Delta t}} $$ (3) 其中,Δt为相邻两点间的时间间隔。
由于车辆在记录行驶时间过程中存在精度误差,为提高数据统计准确性,需要对速度提取后结果进行滤波,笔者采用中值滤波算法得到不同曲率对应的车辆行驶速度,算法流程图如图3所示。计算得到的结果见表2。
表 2 位置点不同曲率半径下评价速度Table 2. Evaluate velocity at different curvature radii at location point序号 曲率半径/m 行驶速度/(km·h‒1) 1 15.0 9.80 2 20.0 11.32 3 25.0 12.65 4 30.0 13.86 5 35.0 14.97 6 40.0 16.00 7 45.0 16.27 8 50.0 17.89 9 60.0 19.60 10 70.0 20.17 11 80.0 22.63 12 90.0 24.00 13 100.0 25.30 14 125.0 27.29 15 150.0 26.99 16 175.0 29.47 17 200.0 30.78 18 225.0 31.95 19 > 250.0 32.5 2.1.3 坡度区间计算
同时,车辆在不同坡度条件下行驶车速特征存在其特征规律,利用数据文件中的高程、速度、时间等字段为每个时间帧计算坡度值。
首先记录起始点,并利用2相邻时间点的实际速度值求取平均速度,再乘以2点时间差算得移动距离,判断该距离是否大于车长,如不大于则加上后续点的移动距离,反复判断过程,直到大于车长跳出判断,并记录当前点高程为前高程,起始点高程为后高程,利用如下公式计算坡度slope:
$$ slope\_initial = \frac{{temp\_rear\_alt - temp\_front\_alt}}{{0.1 \times vehicle\_length \times g}} $$ (4) $$ slope = \tan({\mathrm{asin}}(slope\_initail)) \times 100 $$ (5) 其中,$ temp\_front\_alt $为车辆前高程;temp_rear_alt为后高程;$ vehicle\_length $为车长;g为重力加速度。算法整体结构如图4所示。由此可以求出不同下坡坡度的行驶速度,见表3,求出每个时间点的坡度值后,按照区间分割策略,统计矿卡在不同坡度区间的数据分布,再根据其计算对应的速度分布值,完成基于坡度区间的速度分布统计,如图5所示。
表 3 位置点不同的下坡坡度下的平均速度(重载情况)Table 3. Average speed at different downhill slopes at location points (heavy load conditions)序号 下坡坡度/% 行驶速度/(km·h‒1) 1 1.00 26.75 2 1.50 26.05 3 2.00 25.56 4 2.50 20.56 5 3.00 23.78 6 3.33 28.23 7 3.50 25.57 8 4.00 27.23 9 4.50 28.22 10 5.00 27.08 11 5.50 24.96 12 6.00 27.83 13 6.50 28.65 14 7.00 28.08 15 7.50 31.82 16 8.00 30.46 17 8.50 30.50 18 9.00 32.72 由此可以看出,当同时考虑当前道路的曲率和坡度这2个影响因素后,可以由此拟合出当前矿卡的速度分布。通过收集南露天煤矿道路信息,绘制出了南露天煤矿的有人矿卡车速分布图热力图。这对后续指导露天矿矿卡动态调度模型的开发具有重要的意义。
2.2 车速度预测
选取2022年7月1日南露天煤矿全部矿卡的车载传感器和某气象传感器的全部实时数据。车载传感器按照1 s/次的频率记录车辆行驶途中的状态信息,气象传感器按照20 s/次的频率记录当前地区的气象信息。
由于车载传感器数据的记录频率和气象传感器数据的记录频率不同,需要对数据进行重构,抽取相同时间的车载传感器和气象传感器特征,重新建立数据集[14-17]。
输入输出特征见表4,输入特征包括:设备号、风速、降雨量、气温、湿度、降雪量、经度、纬度、方向角、GPS状态1、GPS状态2、卫星数、高程、当前时间。输出特征为车速。
表 4 输入输出特征Table 4. Input and output characteristics输入 设备号 ID 风速 WindRate 降雨量 RainVolum 气温 Temp 湿度 SD 降雪量 SnowVolum 经度 Longitude 纬度 Latitude 方向角 Direction GPS状态1 GPS1 GPS状态2 GPS2 卫星数 Star 高程 Elevation 当前时间 Time_Float 输出 车速 Speed 将生成的数据集按照8∶2的比例进行划分,选择80%的数据作为训练集,20%的数据作为测试集。训练集共包括565 066条数据,测试集共包括141 267条数据。
2.2.1 基于随机森林的算法预测模型
随机森林是一种集成学习方法,通过组合多个决策树构建了一个鲁棒性强、高性能的分类和回归模型[18]。随机森林的核心思想是构建多个决策树,然后通过投票或平均值来融合这些决策树的结果,以提高模型的准确性和鲁棒性。每个决策树都是在不同的数据子集上训练的,这是通过自助采样(Bootstrap Sampling)实现的。此外,每次分裂决策树时,只考虑特征集的一个子集,这有助于减小决策树之间的相关性。该算法的优点如下[19]:
1)随机森林在各种数据类型和任务中表现出色,包括分类、回归、特征选择等。
2)具有强大的泛化性能,不易过拟合。
3)能够处理大规模数据集,对缺失值和异常值具有鲁棒性。
4)提供了特征重要性评估,有助于解释模型的预测。
随机森林算法的参数十分重要,影响着最后算法的效果。以下是随机森林算法的部分重要参数:
1) 树的数量 (n_estimators): 这是随机森林中树的数量。
2) 树的深度 (max_depth): 树的最大深度控制了树的复杂度。
3) 最小叶节点样本数 (min_samples_leaf): 这个参数规定了每个叶节点上的最小样本数。
4)特征子集大小 (max_features): 随机森林在每次分裂时随机选择特征的子集,以增加树之间的差异性。
5)最小分裂样本数 (min_samples_split): 这个参数规定了每个内部节点上的最小样本数,用于触发节点的分裂。
6) 附加参数: 随机森林还有一些其他参数,如criterion(分裂标准)、bootstrap(是否采用Bootstrap采样)、oob_score(是否计算袋外误差)等,可以根据具体问题进行调整。
在进行参数调整时,一种常用的方法是使用网格搜索(Grid Search)或随机搜索(Random Search),通过尝试不同的参数组合来找到性能最佳的配置。同时,使用交叉验证来评估不同参数设置下模型的性能,以避免过度拟合。最终,根据交叉验证的结果选择最佳参数组合,以建立性能出色的随机森林模型。笔者选择网格搜索算法来进行最优参数的搜索。用训练集训练基于随机森林模型的预测模型,利用得到的模型对预测测试集,最后分析评价测试集的预测结果。
2.2.2 基于XGBOOST模型的预测
XGBoost算法,以其卓越的性能和鲁棒性而著称,是一种梯度提升树算法的改进版本,具有出色的泛化性能,广泛应用于分类、回归、排序、特征选择等任务。XGBoost的核心思想是通过迭代地训练弱学习器,构建一个强大的模型,以最小化损失函数[20]。具体来说,XGBoost采用梯度提升方法,通过在每次迭代中拟合负梯度的估计来改进模型。该算法结合了CART(分类与回归树)和正则化技术,以减少过拟合风险。该算法的优点如下[21]:
1)高性能:XGBoost在大规模数据集上表现出色,具有快速的训练速度和预测速度。
2)强大的泛化性能:XGBoost在各种任务中都有出色的泛化性能,不易过拟合。
3)特征选择:XGBoost能够提供特征的重要性评估,有助于特征选择和解释模型。
XGBoost有多个参数,可以通过调整来优化模型性能。一些关键的参数包括学习率(learning rate)、树的数量、树的深度、正则化项、最小子样本数等。参数调整可以通过网格搜索、随机搜索或贝叶斯优化等方法来完成,以找到最佳参数组合。
用训练集训练基于XGBOOST模型的预测模型,利用得到的模型对预测测试集,最后分析评价测试集的预测结果[22]。
2.2.3 实验结果
基于上述方法在python上进行速度预测模型建模,模型的评价指标对比见表5,车速预测结果见表6,车速真实值与预测值的结果对比如图6所示。
表 5 实验评价指标结果对比Table 5. Comparison of experimental evaluation index resultsMSE RMSE MAE R2 随机森林 1.826 70 1.351 55 0.551 96 0.987 80 XGBOOST 12.291 4 3.505 91 0.917 970 0.917 970 从表5可以看出,基于随机森林的预测模型露天矿山有人矿卡车速预测结果均方误差为1.826 7,决定系数为0.987 80。而基于XGBOOST模型的行程时间预测结果均方误差为12.291 4,决定系数为0.917 97;从表6、图6可以看出,相较于XGBoost算法,随机森林的速度预测值更接近真实速度,由此可以得出基于随机森林模型的车速预测好于基于XGBOOST模型的预测的结果。
表 6 实验结果对比Table 6. Comparison of experimental results真实速度/
(km·h‒1)随机森林速度预测值/
(km·h‒1)XGBoost速度预测值/
(km·h‒1)29.46 29.374 6 27.334 871 0 0 0.332 302 06 20.48 20.493 3 21.027 088 31.18 30.299 2 29.553 146 0 0 0.0485 826 730.79 2.425 8 20.8419 0419.59 19.085 7 19.613 817 0 0 1.710 842 3 25.09 27.606 1 21.975 08 0 0 1.399 853 3 0 0 0.0922 189 2![]() 图 6 速度真实值与预测值的结果对比Figure 6. Comparison of results of true velocity value andpredicted value
图 6 速度真实值与预测值的结果对比Figure 6. Comparison of results of true velocity value andpredicted value通过算法对矿卡速度进行预测在露天矿山中具有重要意义。首先矿卡速度的准确预测可以帮助调度系统更精确地估计矿卡到达时间和离开时间。这有助于更好地协调矿卡的装载、卸载和行驶路线,减少等待时间和资源浪费。其次,速度预测有助于减少矿卡之间的交通拥堵,最大程度地减少排队时间。这对于提高生产效率和减少运营成本至关重要。然后,调度系统可以根据矿卡速度的预测进行更智能的决策,例如,将速度较快的矿卡分配给紧急任务,以提高生产效率。此外,矿卡速度的预测有助于预测潜在的危险情况,如超速行驶,提前采取措施来提高安全性,减少事故风险。最后,准确的速度预测可以为实时决策提供支持,使矿山运营者能够更好地应对不断变化的情况。
3. 结 语
基于机器学习的露天矿卡速度预测在调度系统的应用是一项有前景的技术,可以帮助煤矿和采矿行业优化矿卡的使用和调度,提高生产效率、降低成本,并增加工作安全性。通过使用机器学习算法,可以基于历史数据和实时信息来预测每辆矿卡的瞬时速度,从而求解出到达时间。这有助于调度系统更准确地安排矿卡的装载和卸载任务,减少等待时间和资源浪费。机器学习可以分析多个变量,如矿卡的位置、负载、速度等,以确定最佳的装载和卸载时间和地点。这有助于降低空载行驶、提高装载效率,减少等待和排队时间。通过机器学习模型,可以更好地分配资源,确保矿卡和设备的有效使用。这包括最佳的矿卡配置、维修计划和人员分配。可以提供实时的数据分析和决策支持,使矿山运营者能够更好地应对不断变化的情况。

 下载:
下载:







计量
- 文章访问数: 211
- HTML全文浏览量: 3
- PDF下载量: 426
